Recruiting Farmer Collaborators for 2024 Would you like to better understand and predict the optimum nitrogen fertilizer rate within and across your fields? We’re looking for farmers to participate in
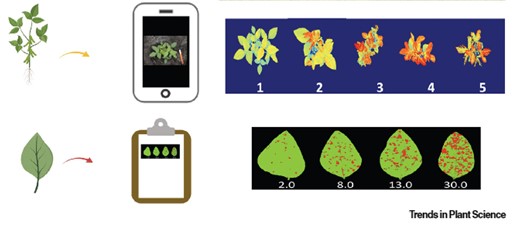
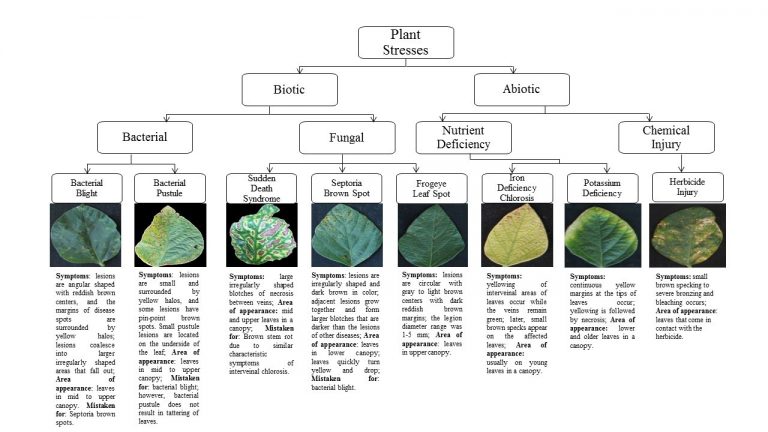
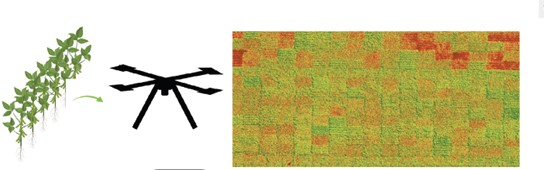
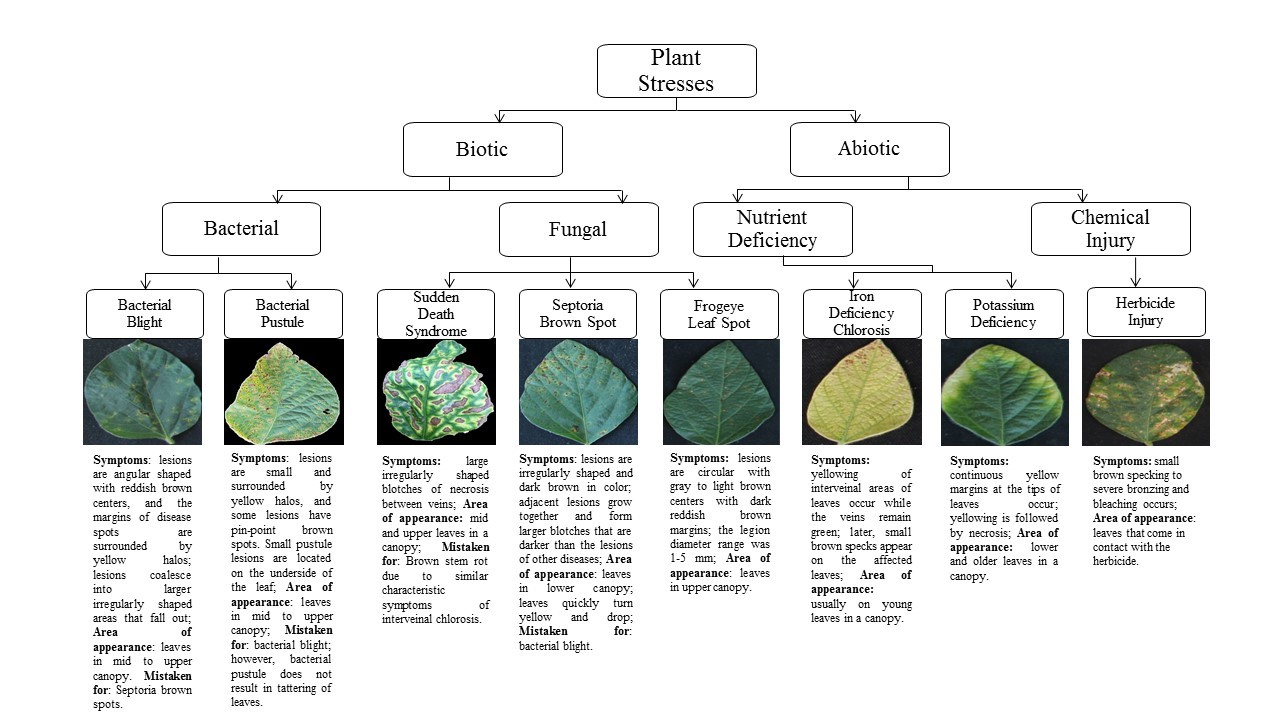
PI – Arti Singh; Co-PI – Baskar Ganapathysubramanian, Soumik Sarkar, Asheesh Singh, Daren Mueller and Greg Tylka The goal of this research is to identify and differentiate biotic stresses under
Co-PI – Asheesh Singh, Baskar Ganapathysubramanian, Carolyn Lawrence, Senior Personnel – Arti Singh and others Currently, the highest priorities for agriculture production are to sustainably meet the food/feed/fuel/fiber requirements of
PI – Arti Singh; Co-PI – Baskar Ganapathysubramanian, Soumik Sarkar, Asheesh Singh, Daren Mueller and Greg Tylka The main objective of the project was to differentiate mutliple stresses in soybean
In this study we investigate how groundwater table depth may influence plant growth above- and below-ground through affecting the vertical distribution of roots. The purpose of this project is to
PI – Sourabh Bhattacharya; Co-PI – Arti Singh, Soumik Sarkar, Baskar Ganapathysubramanian, Asheesh Singh The objective of this project is to build a network of ground robots that can collect
PI – Soumik Sarkar; Co-PI – Arti Singh, Baskar Ganapathysubramanian, Asheesh Singh and Daren Mueller The availability of cheap, deployable, and connected sensor technology has produced a data deluge at
A current cyber-agriculture data need is to improve and standardize data collection protocols and to develop curation processes and infrastructure to support the ability of machine learning (ML) to contribute
Soil is the largest terrestrial source of nitrous oxide. In agricultural cropping systems, nitrous oxide typically represents the largest net greenhouse gas flux. Increases in farm efficiency are well known
Soil organic matter increases crop yield amount and stability. Soil organic matter – not nitrogen fertilizer – is the largest source of crop nitrogen uptake and environmental nitrogen loss. For
Cover crops are an integral component of cropping systems because they grow in the fall and early spring – that is, times when the soil would not have a growing
{kind=link}









{kind=link}